Use Snowflake to Query Existing Data in Backblaze B2
- Print
- DarkLight
Use Snowflake to Query Existing Data in Backblaze B2
- Print
- DarkLight
Article Summary
Share feedback
Thanks for sharing your feedback!
You can create an external table to query an existing, partitioned, data set from Backblaze B2 Cloud Storage using Snowflake. To illustrate how you can access data that already exists in Backblaze B2, this guide uses the Backblaze Drive Stats data set as an example.
Drive Stats is a public data set comprising daily metrics that are collected from the hard drives in Backblaze’s cloud storage infrastructure that we have made available since April 2013. Currently, Drive Stats comprises nearly 389 million records, rising by over 240,000 records per day. Drive Stats is an append-only dataset effectively logging daily statistics that once written are never updated or deleted.
Each day, Backblaze collects a Drive Stats record from each hard drive containing the following data:
- date
The date of collection. - serial_number
The unique serial number of the drive. - model
The manufacturer’s model number of the drive. - capacity_bytes
The drive’s capacity, in bytes. - failure:
1 if this was the last day that the drive was operational before failing, 0 if all is well. - A collection of SMART attributes
The number of attributes collected has risen over time; currently, Backblaze stores 87 SMART attributes in each record, each one in both raw and normalized form, with field names of the form smart_n_normalized and smart_n_raw, where n is between 1 and 255.
In total, each record currently comprises 179 fields of data describing the state of an individual hard drive on a given day (the number of SMART attributes collected has risen over time).
The entire Backblaze Drive Stats data set is made available in Parquet format in a public Backblaze B2 bucket. The data is partitioned by year and month, using the Apache Hive table format, into 163 files occupying 19.1 GB of storage. This partitioning is typical of large data sets, but it complicates the external table definition. In the following sections, you will learn some techniques to manage this complexity.
For more information about using Snowflake with Backblaze B2, see Data-Driven Decisions with Snowflake and Backblaze B2.
Create an External Stage for the Drive Stats Data
Before you begin: Sign up for Snowflake if you do not already have an account. At the time of publication, Snowflake offers a 30-day free trial, including $400 worth of free usage, which is more than enough to work through the following steps and understand how the integration works.
- Enable the endpoint for your Snowflake account by submitting a support case to Snowflake.
- Provide your Snowflake account name and cloud region deployment.
- Provide the endpoint
s3.us-west-004.backblazeb2.com. You must also specify that the endpoint is provided by Backblaze, and that it has been verified using Snowflake's s3compat API test suite.
- Create an external stage for the Drive Stats data by pasting the following unchanged command into the Snowflake console; the application key and its ID are shared read-only credentials:
A response similar to the following example is returned:CREATE STAGE drive_stats_stage URL = 's3compat://drivestats-parquet/drivestats' ENDPOINT = 's3.us-west-004.backblazeb2.com' REGION = 'us-west-004' CREDENTIALS = ( AWS_KEY_ID = '0045f0571db506a0000000007' AWS_SECRET_KEY = 'K004cogT4GIeHHfhCyPPLsPBT4NyY1A' ); - To verify that all of the files were located, run the following command to list the files in the stage:
A response similar to the following example is returned:LIST @drive_stats_stage;
...



Generate the Schema for the Drive Stats Data
You can see the year and month partition columns in each file name in the above listing example. The Apache Hive table format avoids redundancy by dictating that partition columns are not included in the data files. Since the Snowflake external table must include those fields, you cannot directly infer the schema from the data as in the earlier example.
- Run the following command to create a named file format:
A response similar to the following example is returned:CREATE FILE FORMAT parquet_snappy TYPE = PARQUET COMPRESSION = SNAPPY;
If you have already created the file format, you will receive anobject already existserror message when you try to create it again. You should use the existing file format. Do not replace the existing file format, even with a new file format with the same name, or you will lose access to tables that use the existing file format. - Run the following query to have Snowflake infer a schema from the Drive Stats files. Note that
IGNORE_CASEis set to 'TRUE' so that the query does not generate lower-case column names that you have to quote when you query the table:
The query takes a few seconds to run because it scans the metadata for all 163 files. Notice that the following output does not include year or month columns since they are not stored in the data files:SELECT * FROM TABLE( INFER_SCHEMA( LOCATION => '@drive_stats_stage', FILE_FORMAT => 'parquet_snappy', IGNORE_CASE => TRUE ) );
... - Create partition column definitions for the external table that contain expressions to compute the column values from the Parquet filenames. The METADATA$FILENAME pseudocolumn is the starting point; the following query shows a filename for the Drive Stats data:
A response similar to the following example is returned:SELECT metadata$filename FROM @drive_stats_stage LIMIT 1; - Run the following command to parse the year and month from the filename using Snowflake’s SPLIT_PART string function, then convert each of the resulting strings to a numeric value with TO_NUMBER. The command shows the columns if you were writing the table definition by hand:
CREATE EXTERNAL TABLE drive_stats( month NUMBER AS ( TO_NUMBER( SPLIT_PART(SPLIT_PART(metadata$filename, '/', 3), '=', 2) ) ), year NUMBER AS ( TO_NUMBER( SPLIT_PART(SPLIT_PART(metadata$filename, '/', 2), '=', 2) ) ), ... ) LOCATION = @b2_stage/tpch_sf1 FILE_FORMAT = parquet_snappy AUTO_REFRESH = false; - Run the following command to combine those two column definitions with the inferred schema, use the PARSE_JSON function to create VARIANT values. The function that shows the resulting list of columns is
GENERATE_COLUMN_DESCRIPTION:
A response similar to the following example is returned:SELECT GENERATE_COLUMN_DESCRIPTION(ARRAY_CAT( ARRAY_AGG(OBJECT_CONSTRUCT(*)), [ PARSE_JSON('{ "COLUMN_NAME": "year", "EXPRESSION": "TO_NUMBER(SPLIT_PART(SPLIT_PART(metadata$filename, \'/\', 2), \'=\', 2))", "NULLABLE": false, "TYPE": "NUMBER(38, 0)" }'), PARSE_JSON('{ "COLUMN_NAME": "month", "EXPRESSION": "TO_NUMBER(SPLIT_PART(SPLIT_PART(metadata$filename, \'/\', 3), \'=\', 2))", "NULLABLE": false, "TYPE": "NUMBER(38, 0)" }') ] ), 'external_table') AS COLUMNS FROM TABLE( INFER_SCHEMA( LOCATION=>'@drive_stats_stage', FILE_FORMAT=>'parquet_snappy', IGNORE_CASE => TRUE ) )
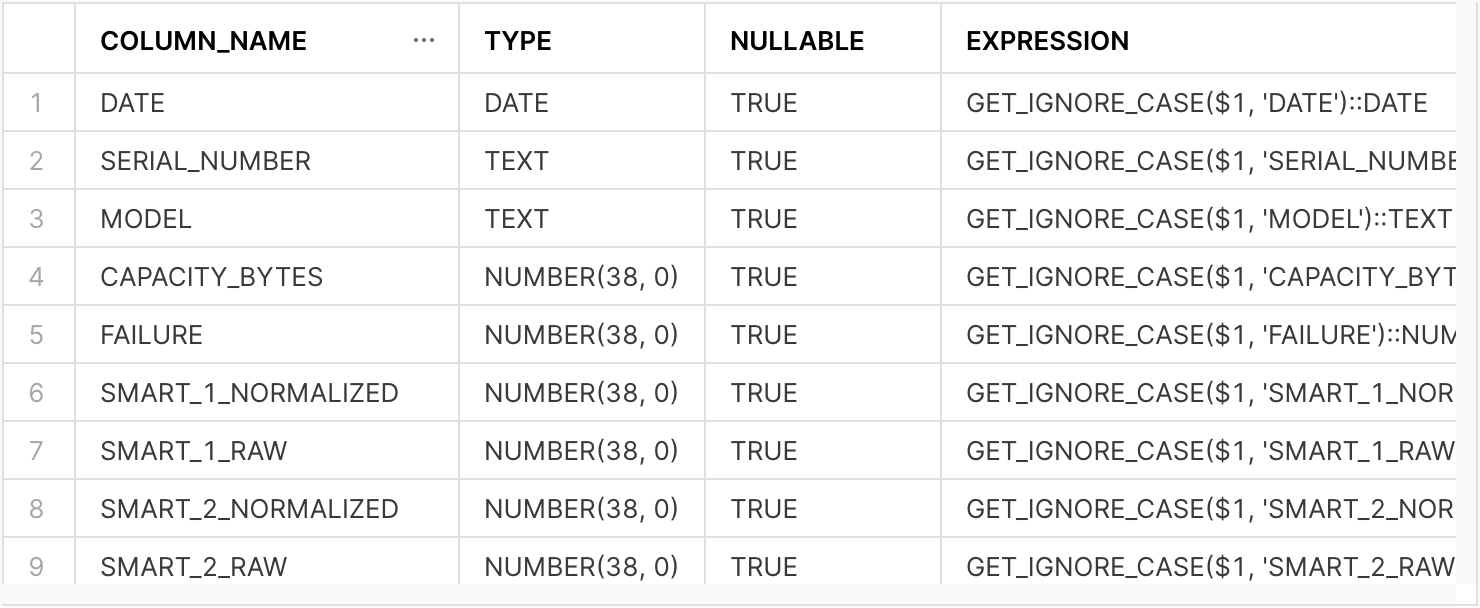
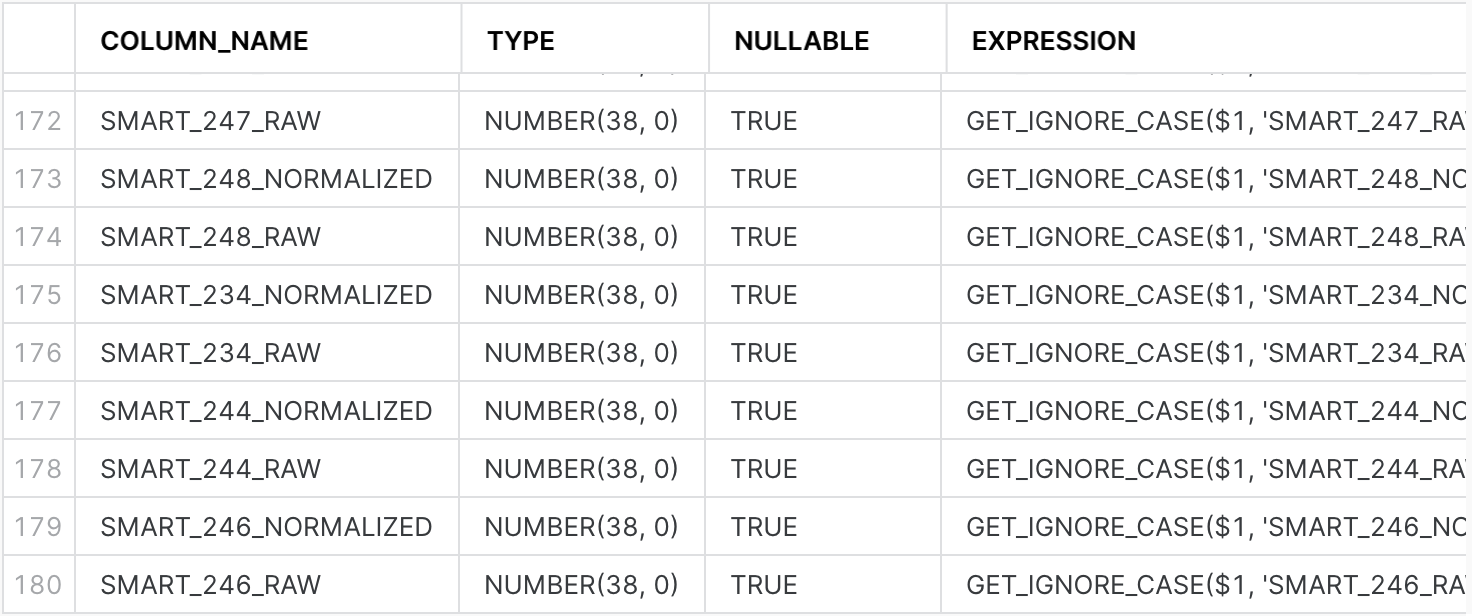
You can reorder and reformat the output to be more readable and to see the column definitions:"DATE" DATE AS (GET_IGNORE_CASE($1, 'DATE')::DATE), "SERIAL_NUMBER" TEXT AS (GET_IGNORE_CASE($1, 'SERIAL_NUMBER')::TEXT), "MODEL" TEXT AS (GET_IGNORE_CASE($1, 'MODEL')::TEXT), "CAPACITY_BYTES" NUMBER(38, 0) AS (GET_IGNORE_CASE($1, 'CAPACITY_BYTES')::NUMBER(38, 0)), "FAILURE" NUMBER(38, 0) AS (GET_IGNORE_CASE($1, 'FAILURE')::NUMBER(38, 0)), "DAY" NUMBER(38, 0) AS (GET_IGNORE_CASE($1, 'DAY')::NUMBER(38, 0)), "MONTH" NUMBER(38, 0) AS (TO_NUMBER(SPLIT_PART(SPLIT_PART(metadata$filename, '/', 3), '=', 2))) "YEAR" NUMBER(38, 0) AS (TO_NUMBER(SPLIT_PART(SPLIT_PART(metadata$filename, '/', 2), '=', 2))), "SMART_1_NORMALIZED" NUMBER(38, 0) AS (GET_IGNORE_CASE($1, 'SMART_1_NORMALIZED')::NUMBER(38, 0)), ... "SMART_255_RAW" NUMBER(38, 0) AS (GET_IGNORE_CASE($1, 'SMART_255_RAW')::NUMBER(38, 0)), - You might expect to be able to write a
CREATE TABLEstatement that combines the inferred schema with the partition columns, but this is not possible. Use the following scripting block to build and run the table creation statement. The code separates schema inference from table creation, builds the table creation statement as a string by concatenating the results of the inference query withPARTITION_BYand other parameters, runs the code in the table creation string, and returns the creation statement's response as the block's output. Since SQL variables are limited to a maximum size of 256 characters, you must use a scripting block rather than a SQL variable.
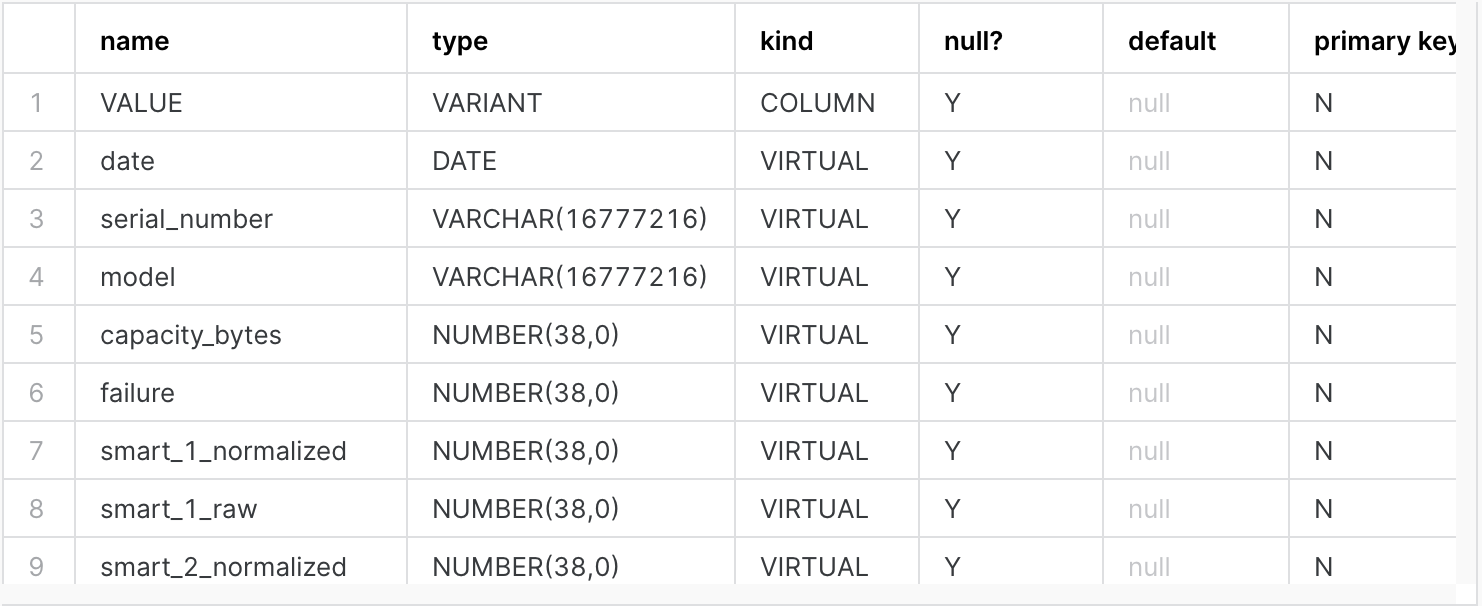
Running the block creates theDECLARE -- In the code below, $$ is the multiline string delimiter. -- $$ lets us include newlines, single and double quotes -- without needing to escape them. -- The script uses || to concatenate literal strings with -- the result of the query to build the table definition. -- result will hold the output from executing the create statement result VARCHAR; -- create_stmt is built from the inferred schema of -- the external data plus manually defined partition columns create_stmt STRING DEFAULT $$ CREATE OR REPLACE EXTERNAL TABLE drivestats ($$ || ( -- Infer the schema from the files in the stage, then add the partition columns SELECT GENERATE_COLUMN_DESCRIPTION(ARRAY_CAT( ARRAY_AGG(OBJECT_CONSTRUCT(*)), -- Partition columns are defined as expressions based on the filename [ PARSE_JSON('{ "COLUMN_NAME": "YEAR", "EXPRESSION": "TO_NUMBER(SPLIT_PART(SPLIT_PART(metadata$filename, \'/\', 2), \'=\', 2))", "NULLABLE": false, "TYPE": "NUMBER(38, 0)" }'), PARSE_JSON('{ "COLUMN_NAME": "MONTH", "EXPRESSION": "TO_NUMBER(SPLIT_PART(SPLIT_PART(metadata$filename, \'/\', 3), \'=\', 2))", "NULLABLE": false, "TYPE": "NUMBER(38, 0)" }') ]), 'EXTERNAL_TABLE') -- Concatenate the table parameters after the query results || $$) PARTITION BY (year, month) LOCATION = @drive_stats_stage FILE_FORMAT = parquet_snappy AUTO_REFRESH = false; $$ FROM TABLE ( INFER_SCHEMA( LOCATION => '@drive_stats_stage', FILE_FORMAT => 'parquet_snappy' ) ) ); BEGIN -- Create the table EXECUTE IMMEDIATE create_stmt; -- Capture and return the output from the table creation SELECT $1 INTO result FROM TABLE(RESULT_SCAN(LAST_QUERY_ID())); RETURN result; END;drivestatsexternal table: - To verify that the results are expected, run the following command:
A response similar to the following example is returned:DESCRIBE TABLE drivestats;




Query the Drive Stats Data
- Run the following command to count all of the records in the Drive Stats files. This takes approximately 25 seconds on a Snowflake X-Small instance, reading about 10 MB of Parquet metadata from the 163 files in the Drive Stats data set:
A response similar to the following example is returned:SELECT COUNT(*) FROM drivestats; - Run the following command to use the partition columns to constrain queries to particular years and months; counting the records for a single month takes just a couple of seconds because Snowflake is reading only 0.06 MB from a single file:
A response similar to the following example is returned:SELECT COUNT(*) FROM drivestats WHERE year = 2023 AND month = 3; - Run the following command to determine how many drives were spinning on the most recent day on record, for example, 3/31/2023. This query takes longer to run than the previous query, approximately 23 seconds because it must read actual data for the daycolumn rather than just the Parquet metadata.
A response similar to the following example is returned:SELECT COUNT(*) FROM drivestats WHERE year = 2023 AND month = 3 AND day = 31; - Run the following command to determine how many drives Drive Stats includes. This query takes approximately three minutes because it reads more than 2 GB of data, all of the serial numbers of all of the drives in the data set, and the metadata that is required to locate them.
A response similar to the following example is returned:SELECT COUNT (DISTINCT serial_number) FROM drivestats LIMIT 10;




References
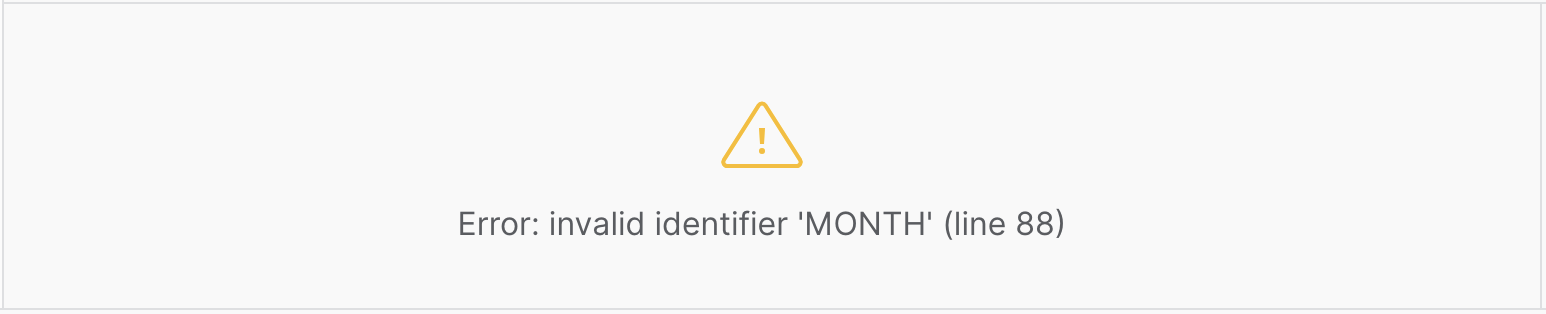
You might expect to be able to write a CREATE TABLE statement that combines the inferred schema with the partition columns, but this is not possible. You can use a scripting block to build and run the table creation statement. The code separates schema inference from table creation, builds the table creation statement as a string by concatenating the results of the inference query with PARTITION_BY and other parameters, runs the code in the table creation string, and returns the creation statement's response as the block's output. (You must use a scripting block rather than a SQL variable since SQL variables are limited to a maximum size of 256 characters.) Use the workaround that is documented in step 6 of the Generate the Schema for the Drive Stats Data task.
-- *** THIS DOES NOT WORK!!! ***
CREATE OR REPLACE EXTERNAL TABLE drivestats
USING TEMPLATE (
SELECT ARRAY_CAT(
ARRAY_AGG(OBJECT_CONSTRUCT(*)),
[
PARSE_JSON('{
"COLUMN_NAME": "YEAR",
"EXPRESSION": "TO_NUMBER(SPLIT_PART(SPLIT_PART(metadata$filename, \'/\', 2), \'=\', 2))",
"NULLABLE": false,
"TYPE": "NUMBER(38, 0)"
}'),
PARSE_JSON('{
"COLUMN_NAME": "MONTH",
"EXPRESSION": "TO_NUMBER(SPLIT_PART(SPLIT_PART(metadata$filename, \'/\', 3), \'=\', 2))",
"NULLABLE": false,
"TYPE": "NUMBER(38, 0)"
}')
]
)
FROM TABLE(
INFER_SCHEMA(
LOCATION => '@drive_stats_stage',
FILE_FORMAT => 'parquet_snappy'
)
)
)
PARTITION BY (year, month)
LOCATION = @drive_stats_stage
FILE_FORMAT = parquet_snappy
AUTO_REFRESH = false;Snowflake does not recognize the partition column names when it parses the query since they are not explicitly listed in the definition:
Was this article helpful?