Recently, artificial intelligence has been having a moment: It’s gone from an abstract idea in a sci-fi movie, to an experiment in a lab, to a tool that is impacting our everyday lives. With headlines from Bing’s AI confessing its love to a reporter to the struggles over who’s liable in an accident with a self-driving car, the existential reality of what it means to live in an era of rapid technological change is playing out in the news.
The headlines may seem fun, but it’s important to consider what this kind of tech means. In some ways, you can draw a parallel to the birth of the internet, with all the innovation, ethical dilemmas, legal challenges, excitement, and chaos that brought with it. (We’re totally happy to discuss in the comments section.)
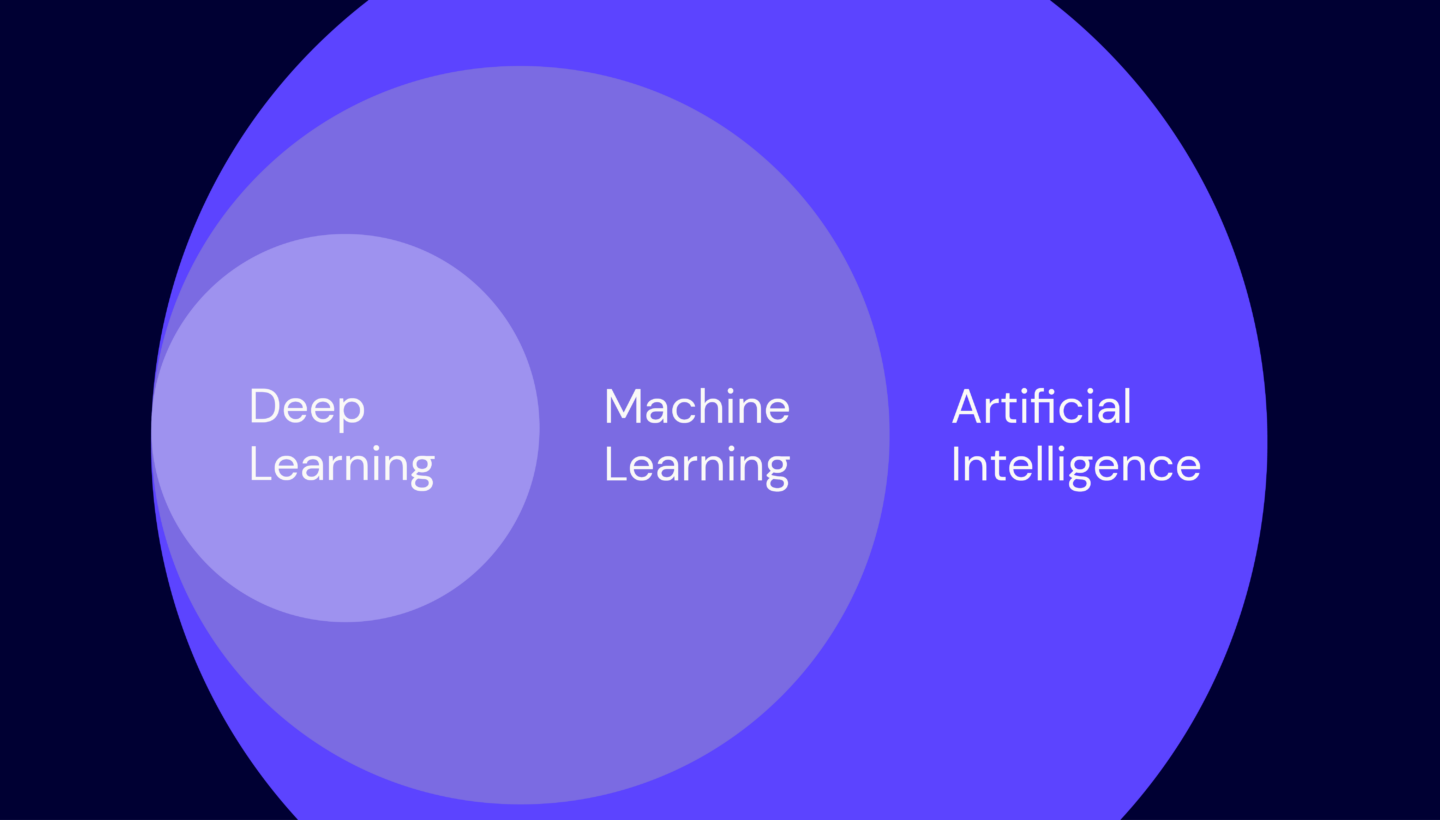
So, let’s keep ourselves grounded in fact and do a quick rundown of some of the technical terms in the greater AI landscape. In this article, we’ll talk about three basic terms to help you define the playing field: artificial intelligence (AI), machine learning (ML), and deep learning (DL).
Want to Know More About AI?
This article is part of an ongoing content arc about artificial intelligence (AI). The second article in the series is AI 101: GPU vs. TPU vs. NPU. Stay tuned for the rest of the series, and feel free to suggest other articles you’d like to see on this content in the comments.What Is Artificial Intelligence (AI)?
If you were to search “artificial intelligence,” you’d see varying definitions. Here are a few from good sources.
From Google, and not Google as in the search engine, but Google in their thought leadership library:
Artificial intelligence is a broad field, which refers to the use of technologies to build machines and computers that have the ability to mimic cognitive functions associated with human intelligence, such as being able to see, understand, and respond to spoken or written language, analyze data, make recommendations, and more.
Although artificial intelligence is often thought of as a system in itself, it is a set of technologies implemented in a system to enable it to reason, learn, and act to solve a complex problem.
From IBM, a company that has been pivotal in computer development since the early days:
At its simplest form, artificial intelligence is a field, which combines computer science and robust datasets, to enable problem-solving. It also encompasses sub-fields of machine learning and deep learning, which are frequently mentioned in conjunction with artificial intelligence. These disciplines are comprised of AI algorithms which seek to create expert systems which make predictions or classifications based on input data.
From Wikipedia, the crowdsourced and scholarly-sourced oversoul of us all:
Artificial intelligence is intelligence demonstrated by machines, as opposed to intelligence displayed by humans or by other animals. “Intelligence” encompasses the ability to learn and to reason, to generalize, and to infer meaning. Example tasks… include speech recognition, computer vision, translation between (natural) languages, as well as other mappings of inputs.
Allow us to give you the Backblaze summary: Each of these sources are saying that artificial intelligence is what happens when computers start thinking (or appearing to think) for themselves. It’s the what. You call a bot you’re training “an AI;” you also call the characteristic of a computer making decisions AI; you call the entire field of this type of problem solving and programming AI.
However, using the term “artificial intelligence” does not define how bots are solving problems. Terms like “machine learning” and “deep learning” are how that appearance of intelligence is created—the complexity of the algorithms and tasks to perform, whether the algorithm learns, what kind of theoretical math is used to make a decision, and so on. For the purposes of this article, you can think of artificial intelligence as the umbrella term for the processes of machine learning and deep learning.
What Is Machine Learning (ML)?
Machine learning (ML) is the study and implementation of computer algorithms that improve automatically through experience. In contrast with AI and in keeping with our earlier terms, AI is when a computer appears intelligent, and ML is when a computer can solve a complex, but defined, task. An algorithm is a set of instructions (the requirements) of a task.
We engage with algorithms all the time without realizing it—for instance, when you visit a site using a URL starting with “https:” your browser is using SSL (or, more accurately in 2023, TLS), a symmetric encryption algorithm that secures communication between your web browser and the site. Basically, when you click “play” on a cat video, your web browser and the site engage in a series of steps to ensure that the site is what it purports to be, and that a third-party can neither eavesdrop on nor modify any of the cuteness exchanged.
Machine learning does not specify how much knowledge the bot you’re training starts with—any task can have more or fewer instructions. You could ask your friend to order dinner, or you could ask your friend to order you pasta from your favorite Italian place to be delivered at 7:30 p.m.
Both of those tasks you just asked your friend to complete are algorithms. The first algorithm requires your friend to make more decisions to execute the task at hand to your satisfaction, and they’ll do that by relying on their past experience of ordering dinner with you—remembering your preferences about restaurants, dishes, cost, and so on.
By setting up more parameters in the second question, you’ve made your friend’s chances of a satisfactory outcome more probable, but there are a ton of things they would still have to determine or decide in order to succeed—finding the phone number of the restaurant, estimating how long food delivery takes, assuming your location for delivery, etc.
I’m framing this example as a discrete event, but you’ll probably eat dinner with your friend again. Maybe your friend doesn’t choose the best place this time, and you let them know you don’t want to eat there in the future. Or, your friend realizes that the restaurant is closed on Mondays, so you can’t eat there. Machine learning is analogous to the process through which your friend can incorporate feedback—yours or the environment’s—and arrive at a satisfactory dinner plan.
Machines Learning to Teach Machines
A real-world example that will help us tie this down is teaching robots to walk (and there are a ton of fun videos on the subject, if you want to lose yourself in YouTube). Many robotics AI experiments teach their robots to walk in simulated, virtual environments before the robot takes on the physical world.
The key is, though, that the robot updates its algorithm based on new information and predicts outcomes without being programmed to do so. With our walking robot friend, that would look like the robot avoiding an obstacle on its own instead of an operator moving a joystick to avoid the obstacle.
There’s an in-between step here, and that’s how much human oversight there is when training an AI. In our dinner example, it’s whether your friend is improving dinner plans from your feedback (“I didn’t like the food.”) or from the environment’s feedback (the restaurant is closed). With our robot friend, it’s whether their operator tells them there is an obstacle, or they sense it on their own. These options are defined as supervised learning and unsupervised learning.
Supervised Learning
An algorithm is trained with labeled input data and is attempting to get to a certain outcome. A good example is predictive maintenance. Here at Backblaze, we closely monitor our fleet of over 230,000 hard drives; every day, we record the SMART attributes for each drive, as well as which drives failed that day. We could feed a subset of that data into a machine learning algorithm, building a model that captures the relationships between those SMART attributes (the input data) and a drive failure (the label). After this training phase, we could test the algorithm and model on a separate subset of data to verify its accuracy at predicting failure, with the ultimate goal of preventing failure by flagging problematic drives based on unlabeled, real-time data.
Unsupervised Learning
An AI is given unlabeled data and asked to identify patterns and probable outcomes. In this case, you’re not asking the bot for an outcome (“Find me an article on AI.”), you’re asking what exists in the dataset (“What types of articles are in this library? What’s the best way to organize this library?”). For example, Google News uses unsupervised learning to categorize articles on the same story from various online news outlets. It recognizes clusters of contemporaneous articles that share key words, and groups them under a suitable heading.
Generative AI: ChatGPT and Bing, DALL-E and Lensa
Most folks’ exposure to AI has been in the form of generative AI. What generative AIs have done that’s revolutionary is to allow us to make a human-speak query to generate “new” material. You can almost think of a generative AI as a DJ with a huge song library—it’s rapidly pulling information from a huge dataset, remixing that information, and presenting you the result.
So, when you ask ChatGPT to write you a story about a spy, they’re going to go back to all the spy text they’ve seen and give you a story based on those patterns. If you ask it to write a story about James Bond, it’s got a more limited dataset with more predictable patterns. If you ask it to write a six sentence paragraph giving you a good spy plot based on James Bond with the main character Oogly Boogly, you might confuse it (or come up with something totally awesome) because “Oogly Boogly” doesn’t really sound like a name you’d see in spy novels.
Obviously We Had ChatGPT Write the Story
And here it is, for your amusement:
In the realm of espionage, Oogly Boogly, a suave and cunning agent, embarks on a high-stakes mission akin to James Bond’s daring escapades. Sent to retrieve a stolen prototype weapon, he finds himself entangled in a web of international intrigue. Posing as a debonair art collector, Oogly infiltrates an extravagant gala hosted by a nefarious arms dealer known only as “The Viper.” With his wit and charm, Oogly seduces the Viper’s right-hand woman, gaining access to the secret underground lair where the weapon is hidden. In a thrilling climax, Oogly engages in a heart-stopping duel with The Viper, narrowly escaping the clutches of death. With the weapon recovered, Oogly delivers a clever one-liner before vanishing into the night, leaving the world in awe of his daring exploits and longing for his next thrilling adventure.
I couldn’t live without knowing the clever one-liner, so I asked ChatGPT: “Based on the previous response, what was Oogly’s clever one-liner?”
As Oogly outwitted The Viper and secured the weapon, he flashed a sly smile and uttered his clever one-liner, “Looks like this snake’s venom has run dry.”
We can only assume that Oogly then put on sunglasses while the CSI: Miami theme started in the background.
As a tool, generative AI certainly has both possibilities and limitations. In order to train an AI, you need huge amounts of data, which can come from various sources—one example is when consumers share data in exchange for free or improved apps or services, as evidenced by some (ahem) surprising photos surfacing from a Roomba.
Also, just to confuse things before we’ve even gotten to defining deep learning: Some people are calling generative AI’s processes “deep machine learning” based on its use of metadata as well as tools like image recognition, and because the algorithms are designed to learn from themselves in order to give you better results in the future.
An important note for generative AI: It’s certainly not out of the question to make your own library of content—folks call that “training” an AI, though it’s usually done on a larger scale. Check out Backblaze Director of Solution Engineers Troy Liljedahl’s article on Stable Diffusion to see why and how you might want to do that.
What Is Deep Learning (DL)?
Deep learning is the process of training an AI for complex decision making. “Wait,” you say. “I thought ML was already solving complex tasks.” And you’re right, but the difference is in orders of magnitude, branching possibilities, assumptions, task parameters, and so on.
To understand the difference between machine learning and deep learning, we’re going to take a brief time-out to talk about programmable logic. And, we’ll start by using our robot friend to help us see how decision making works in a seemingly simple task, and what that means when we’re defining “complex tasks.”
The direction from the operator is something like, “Robot friend, get yourself from the lab to the front door of the building.” Here are some of the possible decisions the robot then has to make and inputs the robot might have to adjust for:
- Now?
- If yes, then take a step.
- If no, then wait.
- What are valid reasons to wait?
- If you wait, when should you resume the command?
- Take a step.
- That step could land on solid ground.
- Or, there could be a pencil on the floor.
- If you step on the pencil, was it inconsequential or do you slip?
- If you slip, do you fall?
- If you fall, did you sustain damage?
- If yes, do you need to call for help?
- If not or if it’s minor, get back up.
- If you sustained damage but you could get back up, do you proceed or take the time to repair?
- If there’s no damage, then take the next step.
- First, you’ll have to determine your new position in the room.
- If you slip, do you fall?
- If you step on the pencil, was it inconsequential or do you slip?
- Take the next step. All of the first-step possibilities exist, and some new ones, too.
- With the same foot or the other foot?
- In a straight line or make a turn?
And so on and so forth. Now, take that direction that has parameters—where and how—and get rid of some of them. Your direction for a deep learning AI might be, “Robot, come to my house.” Or, it might be telling the robot to go about a normal day, which means it would have to decide when and how to walk for itself without a specific “walk” command from an operator.
Neural Networks: Logic, Math, and Processing Power
Thus far in the article, we’ve talked about intelligence as a function of decision making. Algorithms outline the decision we want made or the dataset we want the AI to engage with. But, when you think about the process of decision making, you’re actually talking about many decisions getting made in a series. With machine learning, you’re giving more parameters for how to make decisions. With deep learning, you’re asking open-ended questions.
You can certainly view these definitions as having a big ol’ swath of gray area and overlap in their definitions. But at a certain point, all those decisions a computer has to make starts to slow a computer down and require more processing power. There are processors for different kinds of AI by the way, all designed to increase processing power. Whatever that point is, you’ve reached a deep learning threshold.
If we’re looking at things as yes/nos, we assume there’s only one outcome to each choice. Ultimately, yes, our robot is either going to take a step or not. But all of those internal choices, as you can see from the above messy and incomplete list, create nested dependencies. When you’re solving a complex task, you need a structure that is not a strict binary, and that’s when you create a neural network.
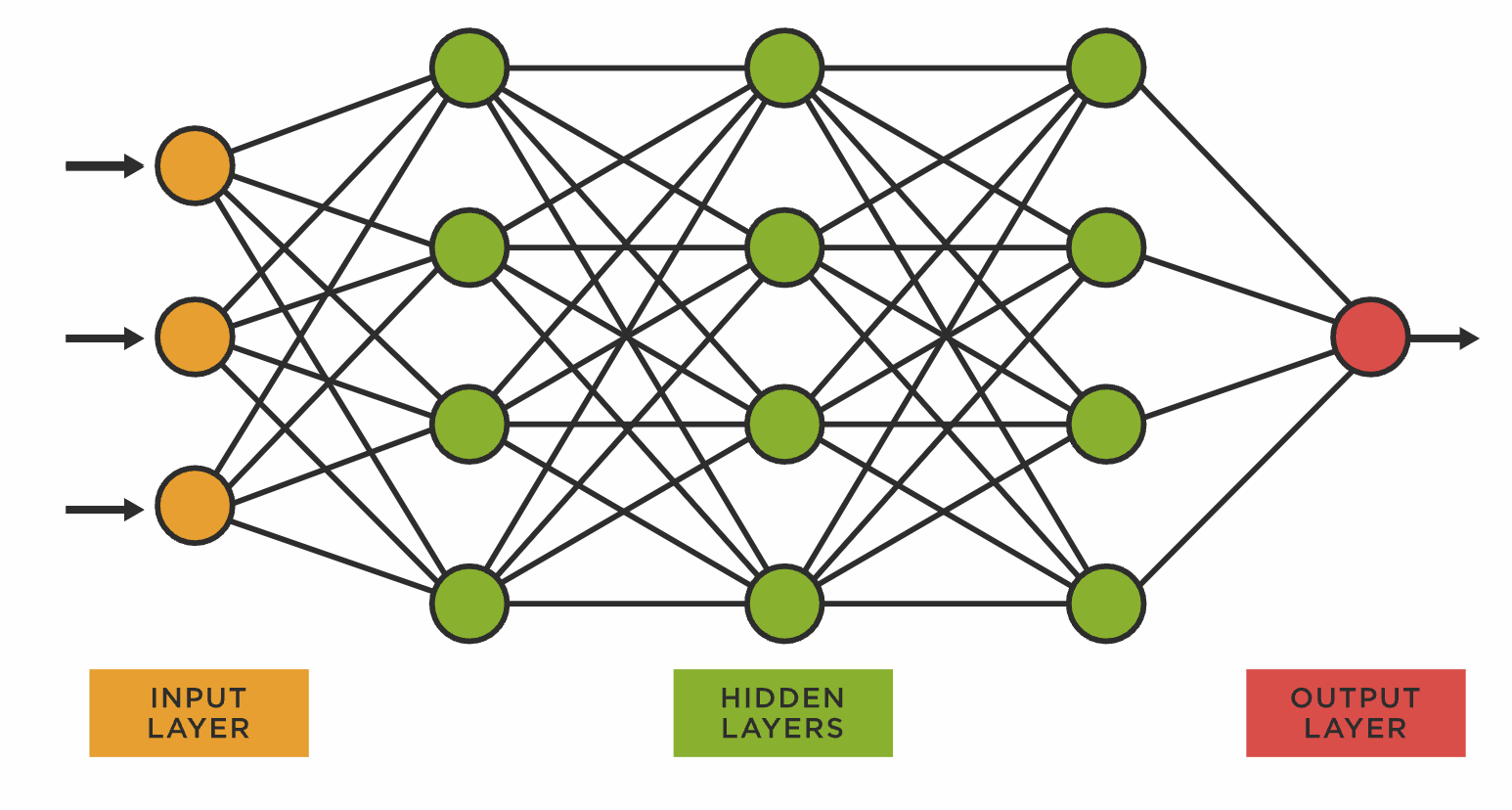
Neural networks learn, just like other ML mechanisms. As its name suggests, a neural network is an interlinked network of artificial neurons based on the structure of biological brains. Each neuron processes data from its incoming connections, passing on results to its outgoing connections. As we train the network by feeding it data, the training algorithm adjusts those processes to optimize the output of the network as a whole. Our robot friend may slip the first few times it steps on a pencil, but, each time, it’s fine-tuning its processing with the goal of staying upright.
You’re Giving Me a Complex!
As you can probably tell, training is important, and the more complex the problem, the more time and data you need to train to consider all possibilities. All possibilities necessarily means providing as much data as possible so that an AI can learn what’s relevant to solving a problem and give you a good solution to your question. Frankly, if or when you’ve succeeded, often scientists have difficulty tracking how neural networks make decisions.
That’s not surprising, in some ways. Deep learning has to solve for shades of gray—for the moment when one user would choose one solution and another would use another solution and it’s hard to tell which was the “better” solution between the two. Take natural language models: You’re translating “I want to drive a car” from English to Spanish. Do you include the implied subject—”yo quiero” instead of “quiero”—when both are correct? Do you use “el coche” or “el carro” or “el auto” as your preferred translation of “car”? Great, now do all that for poetry, with its layers of implied meanings even down to using a single word, cultural and historical references, the importance of rhythm, pagination, lineation, etc.
And that’s before we even get to ethics. Just like in the trolley problem, you have to define how you define what’s “better,” and “better” might just change with context. The trolley problem presents you with a scenario: a train is on course to hit and kill people on the tracks. You can change the direction of the train, but you can’t stop the train. You have two choices:
- You can do nothing, and the train will hit five people.
- You can pull a lever and the train will move to a side track where it will kill one person.
The second scenario is better from a net-harm perspective, but it makes you directly responsible for killing someone. And, things become complicated when you start to add details. What if there are children on the track? Does it matter if the people are illegally on the track? What if pulling the lever also kills you—how much do you/should you value your own survival against other peoples’? These are just the sorts of scenarios that self-driving cars have to solve for.
Deep learning also leaves room for assumptions. In our walking example above, we start with challenging a simple assumption—Do I take the first step now or later? If I wait, how do I know when to resume? If my operator is clearly telling me to do something, under what circumstances can I reject the instruction?
Yeah, But Is AI (or ML or DL) Going to Take Over the World?
Okay, deep breaths. Here’s the summary:
- Artificial intelligence is what we call it when a computer appears intelligent. It’s the umbrella term.
- Machine learning and deep learning both describe processes through which the computer appears intelligent—what it does. As you move from machine learning to deep learning, the tasks get more complex, which means they take more processing power and have different logical underpinnings.
Our brains organically make decisions, adapt to change, process stimuli—and we don’t really know how—but the bottom line is: it’s incredibly difficult to replicate that process with inorganic materials, especially when you start to fall down the rabbit hole of the overlap between hardware and software when it comes to producing chipsets, and how that material can affect how much energy it takes to compute. And don’t get us started on quantum math.
AI is one of those areas where it’s easy to get lost in the sauce, so to speak. Not only does it play on our collective anxieties, but it also represents some seriously complicated engineering that brings together knowledge from various disciplines, some of which are unexpected to non-experts. (When you started this piece, did you think we’d touch on neuroscience?) Our discussions about AI—what it is, what it can do, and how we can use it—become infinitely more productive once we start defining things clearly. Jump into the comments to tell us what you think, and look out for more stories about AI, cloud storage, and beyond.












 Discover the Secret to Lightning-Fast Big Data Analytics: Backblaze + Vultr Beats Amazon S3/EC2 by 39%
Discover the Secret to Lightning-Fast Big Data Analytics: Backblaze + Vultr Beats Amazon S3/EC2 by 39%